Revolutionising AI Chatbots: Advanced Routing Techniques for Enhanced Performance and Efficiency

Ninad Naik
Chief Product Officer, Mira

Sid Doddipalli
Co-Founder & Chief Technology Officer, Mira
AI chatbots have emerged as powerful tools for accessing synthesized and useful information. This has helped transform the workflows of millions of people — from students to researchers to professionals and many more — making them more productive than ever before. Klok (https://klokapp.ai), our specialized, crypto-focused chatbot, is one of the pioneers in this space. It’s made crypto radically more approachable for enthusiasts and professionals.
Today, we discuss some of the novel techniques we’re using to make Klok highly performant and cost-effective, with the goal of making AI viable in business.
Klok at a Glance
Klok is a specialized chat assistant for crypto. It leverages curated content from hundreds of sources including popular media outlets, blogs, and research. This data, combined with our unique architecture, delivers a plethora of powerful features for our users:
The ability to summarize complex crypto-related content, without losing context, into concise, easy-to-understand synopses. This feature is particularly valuable for users who need to quickly grasp the essence of detailed cryptocurrency analyses or market reports.
User-adaptive styles. Different users comprehend and understand concepts differently — so Klok provides pre-templated response styles such as the popular "Explain It Like I'm 5" (ELI5) approach, breaking down complex ideas into simple, accessible language. Klok also employs analogies to help users relate unfamiliar crypto concepts to everyday experiences, making the learning process more intuitive and engaging.
Real-time pricing, which enables users to stay up-to-date with the latest cryptocurrency valuations without needing to switch to separate price-tracking platforms.
Advanced wallet analytics capabilities, to track portfolio performance and receive personalized wallet activity analyses.
Ability to generate social media content based on any source material. Whether it's crafting tweets, creating blog post outlines, or suggesting social media updates, Klok helps users maintain an active and informed online presence in the crypto space.
Challenges with Production AI
Despite the immense potential of AI chatbots, several challenges persist in their development and operation:
High Operational Costs: Generating high-quality responses often requires passing substantial context to frontier models like GPT-4, resulting in prohibitively expensive operations. These cost are often the key driver of business or product viability.
Multi-function Capability Boundaries: Frontier models are trained on internet-scale data but can suffer from increased error rates for domain specific queries. Additionally, large language models (LLMs) have knowledge cutoff dates and cannot answer real-time queries. This constrains the application space for LLMs.
Latency Issues: Especially when leveraging Retrieval-Augmented Generation (RAG) and related solutions, identifying and passing the supporting context to the model can lead to significant delays. As with traditional product use cases, higher latency can lead to lower customer delight and higher churn.
Our Innovative Solution: Advanced Query Routing
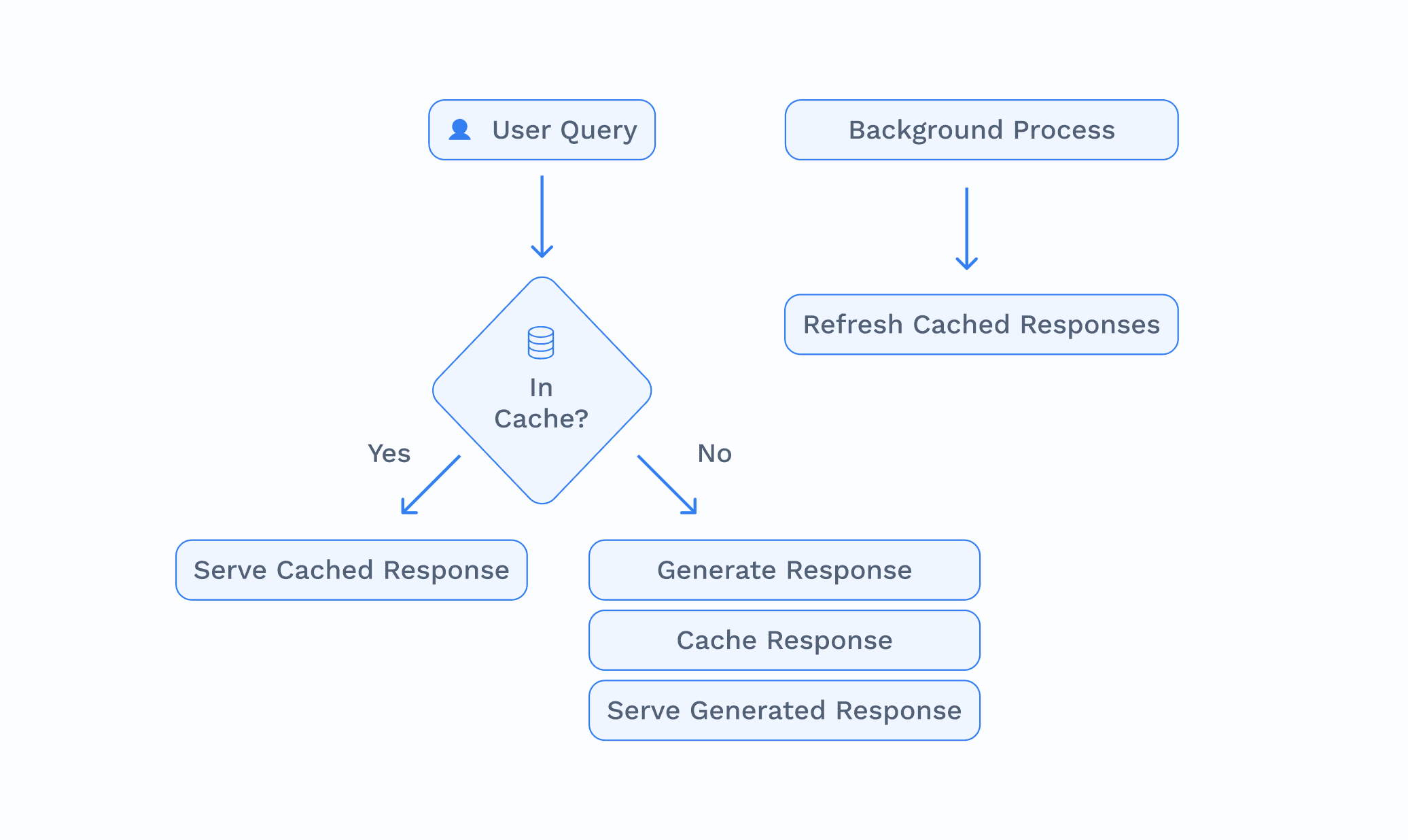
To address these challenges, we've implemented a state-of-the-art routing system that optimizes performance, reduces costs, and enhances the user experience. Here's how it works:
Intelligent Query Evaluation: When a user submits a query, it's first passed to a router that evaluates its nature and content. This router is built in-house and is optimized for performance (latency).
Business Logic Selection: Queries are automatically passed to the most relevant business logic such as a pricing endpoint for token prices, or sub-workflows for other capabilities. This selection logic optimizes for performance (latency).
Pattern Recognition for "Head" Queries: If the query can be answered by an LLM, and if it matches a known pattern of popular or "Anticipiated" queries, it's directed to a retriever.
Efficient Caching System: The retriever accesses a pre-generated, cached response for the query and returns it to the router, which then delivers it to the user. Cached responses are generated using frontier models are are optimized for quality (since the marginal cost of response is ~zero).
Selective LLM Utilization: Only queries that can't be addressed through caching or API calls are routed to the Large Language Model (LLM) for real-time processing. This step is optimized for performance per dollar.
Alert: LLMs Are Only One Piece of the Puzzle
Within queries that require an LLM-class response, we categorize all content as either Anticipated (defined as any query <> context pair that has been previously seen by the system) or Novel (1 - Anticipated).
All Anticipated queries are cached; once cached, all user queries are served from the cache.
An example of an Anticipated query is a pair (query <> context) of any query structure we support by default (e.g. “ELI5 this article” or “Explain this article using an analogy” or “Summarize this for me”) and any content already in our database.
Anticipated queries have a higher likelihood of being asked by customers because we promote them; therefore, we pre-generate responses using the best models (GPT4-class) and cache them, ensuring ~zero marginal cost of delivery and much lower latency than a run-time call to an LLM.
To keep the content fresh, we regenerate responses for Anticipated queries at a regular cadence (T) where T is determined based on the query context. For example, the cached response for “What is Bitcoin?” does not need to be updated more than once every few months.
Responses to Novel queries are generated in real-time.
For queries related to current or unseen topics, we generate responses using models that are in the top-tier of output quality and cache these responses; as the frequency of these questions (N) rises, we re-generate them with the best models and start serving them updated, higher quality responses from cache.
This approach allows us to answer a breadth of user queries in a reliable manner while minimizing our costs.
The Benefits of Our Approach
This innovative routing system offers several key advantages:
Optimized Response Quality and Speed: Users receive high-quality responses (generated from top-tier models) with minimal latency for the most common query types.
Cost Efficiency: By reserving LLM usage for truly novel queries, we significantly reduce operational costs. This efficiency allows us to use premium models for generating cached responses without concerns about run-time expenses.
"Mixture of Experts" Approach: Our system leverages the most appropriate "business logic" for each query type, ensuring optimal handling of diverse user needs.
Technical Implementation and Future Directions
Our implementation leverages cutting-edge technologies to achieve these performance enhancements:
Vector Databases: We utilize vector databases for efficient storage and retrieval of cached responses. This allows for rapid similarity searches, crucial for identifying recurring questions.
Advanced Similarity Matching: We're continuously refining our techniques for identifying similar queries, using a combination of LLM-based prompts and historical answer comparisons.
Looking ahead, we're excited about the potential advancements in this field. We're exploring:
Enhanced Caching Strategies: Developing more sophisticated algorithms to predict and pre-cache likely user queries. We currently cache a large corpus of query <> context pairs; as we scale, we plan to develop query prediction algorithms to reduce the number of queries to support in caching. We will also invest in models to more accurately predict the refresh cadence of responses.
Dynamic Routing Optimization: Implementing machine learning techniques to continuously improve our routing decisions based on user interactions and system performance.
Expanded Knowledge Integration: Investigating methods to seamlessly incorporate real-time data sources and expert knowledge into our response generation pipeline.
Conclusion: Paving the Way for Next-Generation AI Chatbots
Our key recommendation to fellow builders is this: don’t use LLMs for the sake of using LLMs. LLMs are not a one-size-fits-all answer to all problems, especially as you scale from exciting demo to production reality. We believe that the most user-delighting experiences can be built by leveraging LLMs for baseline content generation (volume) — with human in the loop curation — and to tackle novel user requests.
At Mira, we’re building the underlying tools to accomplish these tasks quickly and cheaply. Reach out to us if you’re looking to scale your demo into a robust and viable product. We’d be more than happy to help!
© 2024 Mira. All rights reserved.