Taming the AI Beast: How Our Ensemble Evaluation (EE) Approach is Making Language Models Trustworthy

Ninad Naik
Chief Product Officer, Mira
At Mira, we're not just pushing the boundaries of artificial intelligence – we're completely rethinking them. Our team has been working on one of the most pressing challenges in the world of Large Language Models (LLMs): the notorious "hallucination" problem. You've probably heard about it – those moments when an AI confidently produces something that sounds plausible but is entirely fictional. We're proposing a novel solution to address such issues.
The Promise and Peril of Large Language Models
Let's start with the basics. Large Language Models like GPT-4 have revolutionized the AI landscape. These models, trained on vast amounts of text data, have shown remarkable abilities in tasks ranging from creative writing to complex problem-solving. They've opened up possibilities we could only dream of a decade ago – from generating human-like text to providing insights across various fields of knowledge.
But here's the catch: these models, for all their power, have a critical flaw. They can sometimes produce outputs that are convincingly plausible yet entirely incorrect. It's not that they're trying to deceive; rather, they're making connections and generating responses based on patterns they've learned, without a true understanding of the real-world implications.
Think of it like this: imagine a child who, after visiting a zoo, excitedly tells you their favorite animal was a "Rainbow Python." It sounds vivid, colorful, and entirely believable in a child's imagination. But Rainbow Pythons don't exist. This is analogous to how LLMs can sometimes generate responses that sound correct and fit the patterns they've learned but are detached from reality.
The Hallucination Challenge
This phenomenon, often referred to as AI "hallucinations," poses a significant challenge for the widespread adoption of LLMs in critical applications. Imagine relying on an AI for medical advice, financial decisions, or legal interpretations, only to find out later that the information was fabricated, albeit convincingly. The consequences could be dire.
The root of this problem lies in how LLMs operate. These models are trained on vast amounts of text data, learning patterns and relationships between words and concepts. They can generate coherent and contextually appropriate responses, but they don't truly "understand" the information in the way humans do. They're pattern-matching machines, not reasoning entities.
This leads to a fundamental question: How can we harness the power of LLMs while ensuring their outputs are trustworthy and accurate?
Enter Ensemble Generation: Our Game-Changing Solution
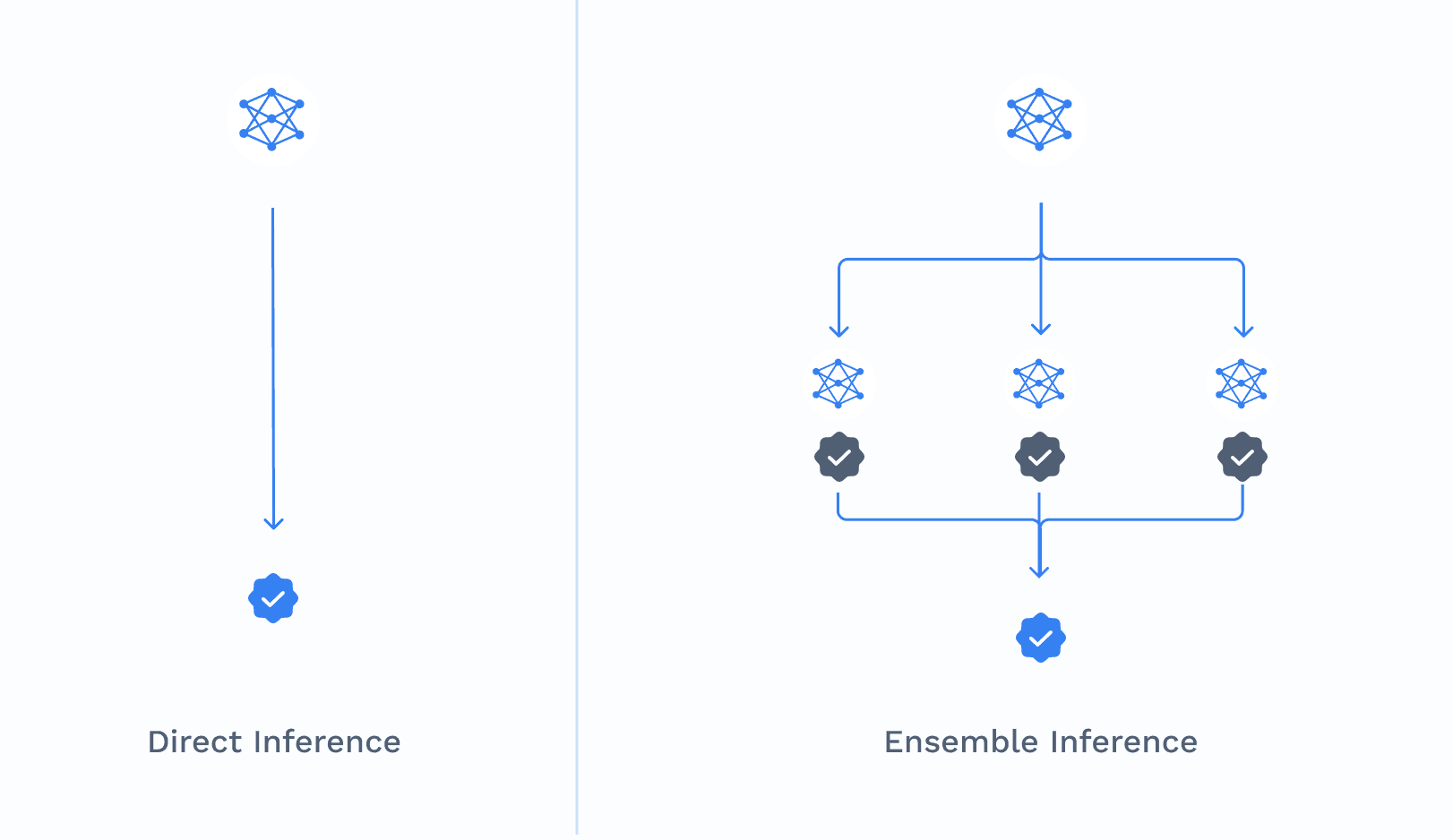
This is where our groundbreaking work at Mira comes into play. We've developed an innovative ensemble generation approach that's making LLMs more trustworthy than ever before. Think of it as assembling a panel of AI experts, each cross-checking the others' work. It's not just smart; it's revolutionary.
Here's how it works:
Generator Model: We start with a "generator" model that creates an initial output based on the given prompt or query.
Evaluator Models: This output is then passed through a gauntlet of "evaluator" models. These evaluators act like a discerning panel of experts, scrutinizing every aspect of the generated content.
Consensus-Based Validation: Only when there's a consensus among these evaluators do we green-light the output.
The Mathematics Behind Our Magic
Beyond the theory, our team has dived deep into the mathematics of this process, using probability theory to fine-tune our approach, and productize this method.
We're talking about leptokurtic and platykurtic distributions – terms that might sound complex but are crucial to understanding the variability of AI outputs. A leptokurtic distribution has heavier tails and a higher, sharper peak compared to a normal distribution. On the flip side, a platykurtic distribution has lighter tails and a lower, flatter peak, representing more consistent and predictable outputs.
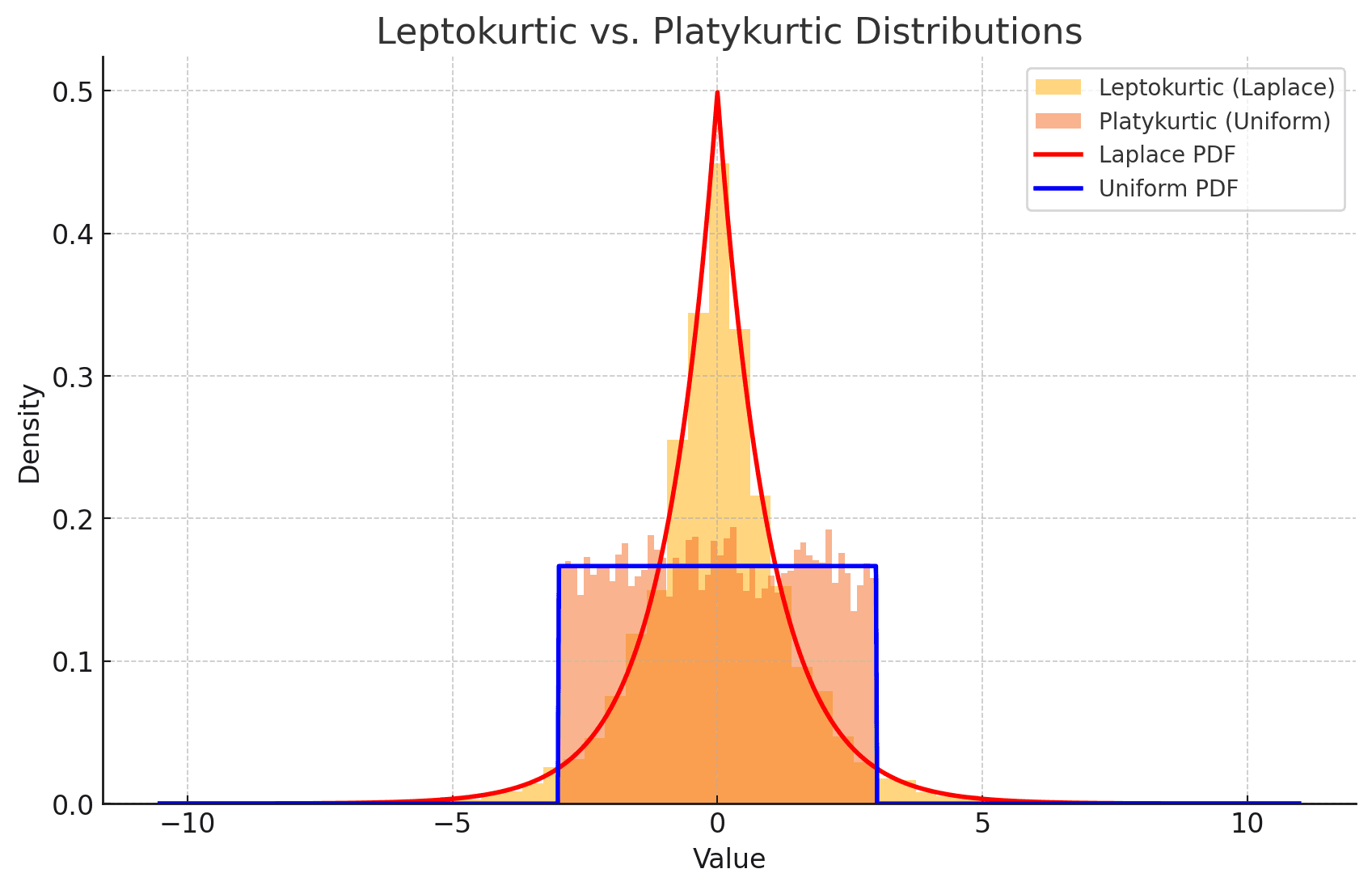
We use ensemble evaluation in cases where we need a narrower distribution of outcomes; this is typically associated with factual responses where creativity is less valued than reliability.
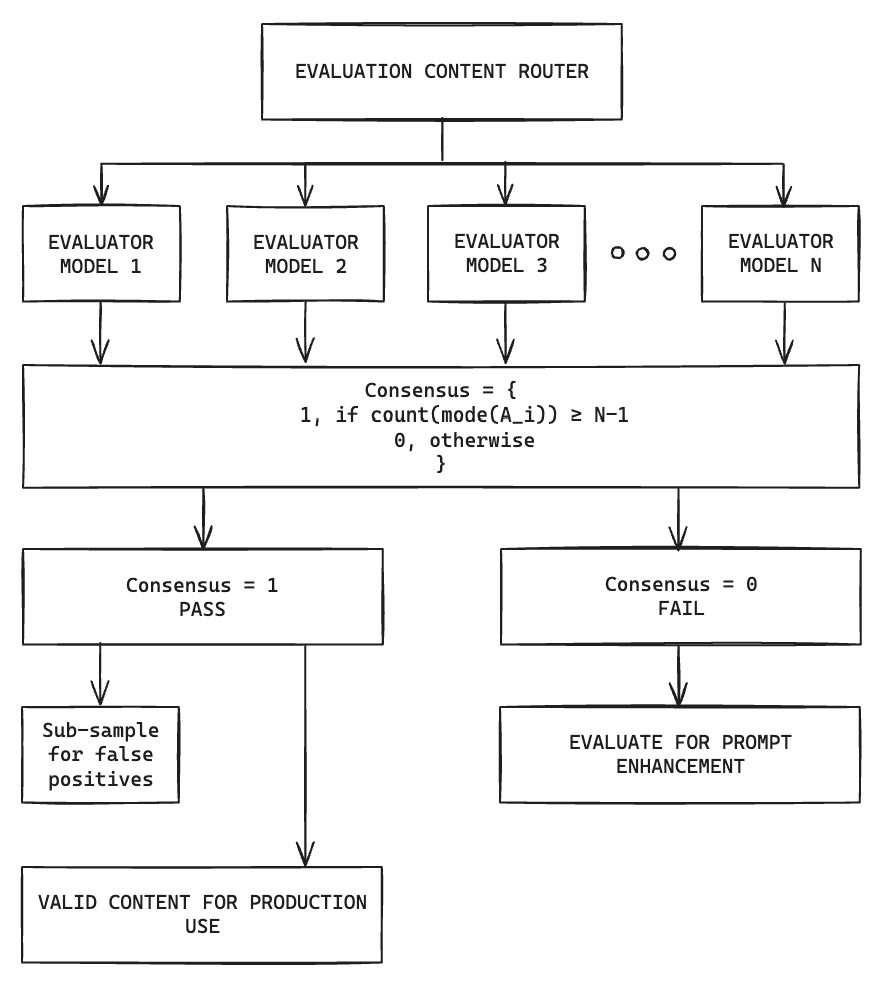
The Consensus Model: Where the Magic Happens
The heart of our system lies in its consensus model. Our mathematical formula to ensure a high level of agreement among our validator models:
Where A_i is the set of answers from validator models for a given question or output, and N is the total number of models.
The final consensus is reached if the average consensus across all questions meets or exceeds a predefined threshold:
This might look like alphabet soup to some, but it's the secret sauce that makes our system so effective. Our system only accepts outputs when there's near-unanimous agreement among the validators, ensuring a high degree of reliability.
Let’s review two examples, one where validator models agree on a correct question, and another where they disagree on the correct question.
In the above example, the generator model (Claude 3.5 Sonnet) generated a question-answer pair based on a question template and source content. It also suggested an expected answer (c) as part of its generation. The expected answer was then stripped and the question block and answer options were passed to evaluator models (Mistral, GPT 4o, Claude 3.5 Sonnet) for a response. All three evaluator models agreed on the correct answer (c) which agreed with the intended answer, and this question-answer pair was deemed valid.
In the above example, the generator model (Claude 3.5 Sonnet) generated a question-answer pair based on a question template and source content. It also suggested an expected answer (a) as part of its generation. The expected answer was then stripped and the question block and answer options were passed to evaluator models (Mistral, GPT 4o, Claude 3.5 Sonnet) for a response. Unlike in the previous example, in this example the validation criteria was set to N of N, meaning that all three evaluator models must agree for the question-answer pair to be deemed valid. Since one evaluator model did not agree with the other two, this question-answer pair was deemed not valid. Interestingly, the correct answer for this question is (b) whereas the question had an expected answer of (a), so this question was correctly sidelined.
Real-World Impact: Beyond the Numbers
Now, you might be thinking, "This all sounds great in theory, but what about real-world applications?" We're glad you asked. We've already implemented this system in production in generating interactive quiz questions from website and textbook content for a client building educational testing software. Imagine being able to automatically create engaging, accurate quizzes for employee training, customer education, or even personalized learning – that's the power of our ensemble approach.
But that's just the tip of the iceberg. The implications of our work extend far beyond just improving AI accuracy. We're opening doors to using AI in fields where trust is paramount:
Healthcare: AI assistants that doctors can rely on for second opinions or rare disease identification.
Finance: Financial advisors that can trust AI-generated market analyses and investment strategies.
Legal Services: AI systems that can accurately summarize case law and predict legal outcomes.
Education: Personalized learning assistants that adapt to each student's needs while ensuring factual accuracy.
The Future of AI: Trustworthy, Reliable, and Human-Centric
At Mira AI, we're not just participating in the AI revolution; we're helping shape it. Our ensemble evaluation approach is setting new standards for AI reliability and trustworthiness. For businesses looking to leverage the power of AI without the risk of embarrassing or costly errors, our solution is a game-changer.
Our team is constantly pushing the envelope, exploring ways to make our system even more efficient and scalable. We're tackling challenges like computational overhead and model diversity head-on, ensuring that our solution isn't just effective, but also practical for businesses of all sizes.
As we continue to refine and expand our technology, we're excited about the possibilities that lie ahead. We're not just making AI smarter; we're making it more trustworthy, more reliable, and ultimately, more human.
The Dawn of Truly Dependable AI
Our ensemble evaluation approach isn't just an incremental improvement – it's an early sign of a paradigm shift in how we think about and interact with AI systems.
We're building a future where businesses can confidently deploy AI solutions without the nagging worry of potential embarrassing or costly errors. A future where AI assists and enhances human decision-making across all sectors of society, from healthcare to education to finance.
This is more than just technology; it's a revolution in trust. And we're just getting started. Stay tuned – the future of trustworthy AI is here, and it's ensemble all the way.
© 2024 Mira. All rights reserved.